
Efficient Multitask Learning Possible with a Predictive Model for Door Opening and Entry
By Sonali Roy View In Digital Edition
Robust models can help robots effectively perform the tasks that humans are habituated to do regularly. The maintenance of such robotics applications involves a considerable amount of developmental costs so that they can keep up with adjustments and adaptations over time. Moreover, what humans cannot contemplate may be initiated by robots such as new motions and optimal trajectories, though the processing may bring up the cost of learning quite a bit that counts on trial and error in the practical world.
However, Hiroshi Ito, Researcher, Research and Development Group, Hitachi Ltd., Japan; Kenjiro Yamamoto, Chief Researcher, Research and Development Group, Hitachi Ltd., Japan; Hiroki Mori, Guest Associate Professor, Institute for AI and Robotics, Waseda University, Japan; and Tetsuya Ogata, Professor, Faculty of Science and Engineering, Waseda University, Japan have developed a system that can perform complicated tasks in the real world with a method that focuses on low design and teaching costs that can reduce the errors.
H. Ito implemented and experimented with actual deep learning models and robot systems, and improved the models through these experiments. K. Yamamoto proposed evaluation metrics and implementation methods to improve the perfection of the models from the viewpoint of practical application to real robot systems.
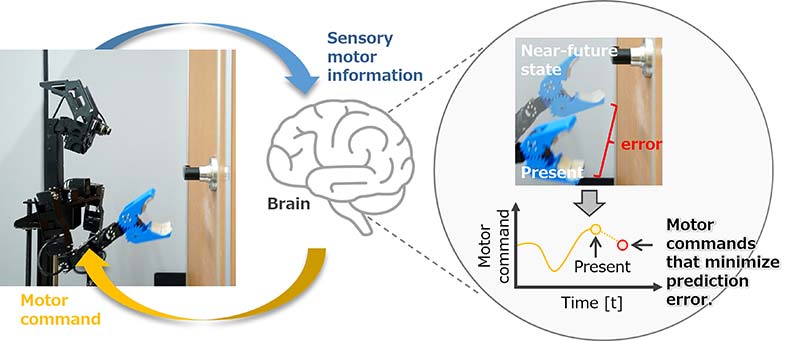
Overview of deep predictive learning: Robot predicts near-future sensory and motor information in real time based on visual and motion time-series information.
H. Mori pointed out the importance of explanatory properties of deep learning models — especially after learning — and proposed methods for model visualization and analysis. T. Ogata proposed an initial overall model and research directions based on his experience in cognitive developmental robotics.
These researchers have introduced a mechanism that uses modules based on the prediction error of multiple modules. Thus, they engineered a module integration method. The device produces motions that call out to the door’s position, color, and pattern with a low teaching cost. The researchers also target at establishing that it’s possible to switch on to sequential tasks that may involve the link-up of multiple modules and responses to sudden situational changes and operating procedures as well
The sequential tasks may engage with opening doors outward and passing through. This research establishes that the device can operate without human interference while keeping in line with the changing environment (https://www.science.org/doi/10.1126/scirobotics.aax8177).
How were the researchers inspired & motivated?
Professor Ogata explains, “Our proposed model, deep predictive learning, had already achieved the task of folding towels in 2016. In the phase of setting our next target, we focused on the great challenge of performing coordination of the whole-body movements such as dual-arms and vehicle.”
What formula of the natural model did the researchers use?
The researchers used a framework that goes in line with ‘active inference.’ Most interestingly, ‘active inference’ is one of the traits of K. Friston’s free energy principle. This includes the principle of inferring or generating perception and action that aims at minimizing variational free energy. The principle engages with free energy as the sum of prediction error and complications. The current method chiefly uses prediction errors.
What are the features of the current system?
According to Professor Ogata, “The current mainstream approach, reinforcement learning, usually requires many learning trials to optimize learning to maximize the acquired rewards.” He continues, “The proposed deep predictive learning assumes that model learning is always incomplete, i.e., there is an unavoidable prediction error, and this generates behaviors in real time to minimize the error. As a result, the number of required training trials can be significantly reduced.”
How did the researchers construct this model and what materials did they use?
The device uses the combined technology of deep predictive learning modules. These modules can learn single tasks that may include approaching a door, opening a door, and passing through a door. There are the CNN-Autoencoder and the Multi-Timescale RNN or MTRNN. The CNN-Autoencoder compresses high dimensional images into low dimensional information. The Multi-Timescale RNN or MTRNN predicts multimodal time-series information.
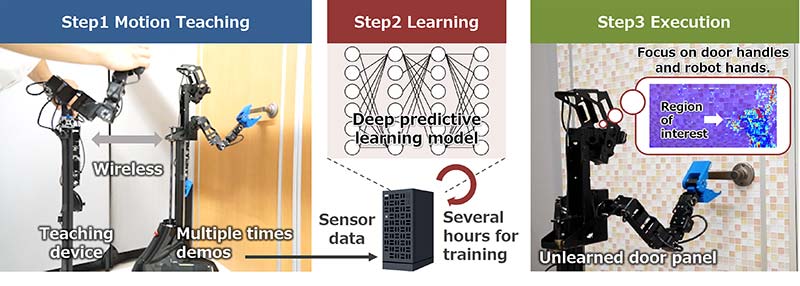
Procedure of deep predictive learning: By simply performing remote motion teaching and model learning, robots can respond to unlearned situations based on experience.
Was there any earlier research on the current finding?
Professor Ogata shares, “Although there have been many studies of robots opening and passing through doors for many years, they usually require human intervention (e.g., designing an environment model, developing a recognition system, developing a control system, adjusting noise in a real environment, etc.).” He goes on, “Our method can achieve the target robot task only by teleoperation (remote control) and learning, decreasing many of these processes.”
What is the mechanism used in constructing the present exploration?
The researchers have trained the modules of deep predictive learning so that these can predict sensation and motion while executing tasks. The sensation may involve visual images. When they ran the system, the researchers opted for the module with the lowest prediction error for the real sensation.
The module also had motion. Actually, these were dynamically selected. The selected modules can create a virtual sensory motor in real time. The real sensory motor and the module’s virtual sensory motor collaborate with each other to minimize the prediction error. The researchers used the output of this virtual motion for the movement of the robot.
The Positional Generalization of the Module
Dr. Ito explains, “Deep Predictive Learning can perform motions with generalization performance even in untaught positions by interpolating multiple positions taught.” The study displays the success rate of the door-opening motion at the taught and untaught positions when the robot was shifted back and forth, left, and right, at 2.5 cm intervals. Dr. Ito analyzes, “The bold numbers in the success rate table indicate the positions where the robot was taught the motion, and the fine numbers indicate the positions where it was not taught it.”
The positioning of each cell connects to the positions. The researchers attempted the door-opening motion 10 times at each position for a total of 250 times. The experiment confirmed that it produced the motion with a success rate of 80% or higher — maybe around 96.8% at all positions. This success test was shown as the robot grasping the door handle and pushing the door open.
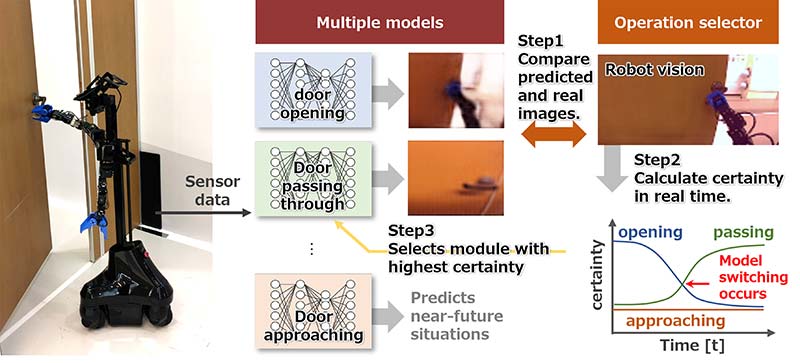
Real time switching of multiple prediction models: The operation selector calculates the image prediction error of each module and actual camera images, and selects the module with the highest certainty as the robot’s motion command. This mechanism allows the robot to respond to sudden changes in a situation and changes in operating procedure.
Insights into the Module Robustness to Environmental Changes Regarding the System
The study confirms that the door opening can be executed with a success rate for untaught door patterns. The door can be opened on the conditions that the color and shape remain similar to the taught ones though the robot tended to fail if the color of the door handle conflicted with the door handle used for training.
What are the success stories of door-opening motion?
Dr. Ito explains that the “success in door-opening motion was defined as the robot grasping the door handle and pushing the door open.” He continues, “Success in door opening and passing through motion was defined as that the robot performed a series of motions: approaching the door, opening the door, and passing through the door.”
As far as the failure cases are concerned, the robots hardly failed while performing their tasks because they received changes in motor dynamics as made by motor heat and generation, and low battery voltage.
Description of the Series of Motions by Module Integration
The researchers integrated three modules focusing on learning of the door-approach motion, door-opening motion, and door-passage motion, respectively. Certainty and motor command of each module are foreseen in real time. Notably, the researchers selected the module with the highest certainty for generating a suitable operation for the situation. The module can be switched adaptively as the situation calls for it, such as what happens in the case of any disturbances.
What is the module scalability regarding the system?
The study confirms that up to six modules can be computed in parallel and in real time as well. Dr. Ito observes, “However, the extraction of image features is time-consuming, so the robot cannot be used for tasks such as chip mounting of semiconductors or high-speed grasping of objects flowing on a conveyor belt.” Dr. Ito continues, “Hardware implementation of the DPL module in an FPGA or improvement in the computing speed of computers may enable high-speed object manipulation and parallel computing of more modules.”

Real time reaching motion to the door handle based on the positional relationship between the robot and the door panel.
The Module Switching Against Disturbance
Generally, the robot uses the sequential techniques of the door-approach, door-opening, and door-passage motions. However, an exception occurs when a person moves the robot to its initial position when it was in the middle of opening the door.
On returning to its initial position, the robot creates the door-approach motion again and eventually passes through the door.
The Interference Task of the Robot
Usually, the robot produces a door-opening motion after it approaches the door. However, if a person opens the door first, it can lead to disturbance. The robot skips the door-opening motion and generates the door-passage motion as the door opens suddenly.
The design cost holds on a good stand in conventional method because as Dr. Ito explains, “it is necessary to separately program responses to external disturbances in addition to the assumed sequence of operation.” In the proposed method, Dr. Ito sums up, “modules are switched automatically on the basis of certainty, there is no need to design the switching timing strictly.”
He continues, “Furthermore, since the system predicts multiple modules’ certainty and motor commands in real time, it is possible to respond to sudden changes in a situation and changes in operating procedure.” You should devise the competing part of each module.
As the multiple behaviors in a single model are concerned, the current finding shows that one motion is learned in one model. Accordingly, multiple models with different learning motions are arranged in a plurality of models and switched as the situation demands.

Door opening and entry with whole-body control.
What was the result of the researchers testing the hypothesis?
According to Professor Ogata, “We succeeded in generating more adaptive behavior than expected in the real environment.” He carries on, “Our proposed method executes appropriate actions in real time based on predictions; it is possible to respond to sudden changes in a situation and changes in operating procedure.”
Professor Ogata further opines that in comparison to the conventional method, the design cost is an issue because it’s necessary to separately program responses to external disturbances in addition to the assumed sequence of operation. Moreover, when a disturbance exists, the problem is that the robot moves slowly as it takes time to recognize a situation and re-plan the trajectory.
What is the most interesting point about this system?
The current system differs from other conventional methods in that it achieved extreme stability and robustness while operating the whole-body movement of a multi degree-of-freedom mobile manipulator over a long period of time by using learning only. Most interestingly, the current exploration eradicates many manual development processes. The method also concentrates on the idea of active inference while designing the robot. Active inference is a model of brain cognitive science.
Regarding the applications of the current system in the real world, Professor Ogata says, “The basic model of our deep predictive learning has already been put into practical use by several companies in Japan.” The companies include ExaWizards Inc., DENSO WAVE Incorporated, and TAISEI Corporation. He expects, “As for our contribution to the development of brain science, we believe we can propose explanatory models for neurodevelopmental disorder using robots and predictive learning models.”

Robot uses both arms to open the inward-opening door.
The Importance of the Current Device in Respect to Cost and Energy Efficiency
As Professor Ogata explains, “From the viewpoint of developmental cost, our method can eliminate many manual development processes such as designing an environment model, developing a recognition system, developing a control system, and adjusting noise in a real environment, etc.”
He continues, “From the viewpoint of energy efficiency, though the system uses a computational power for GPUs, it can run over 1.5 hours thanks to the recent advanced edge processors like a NVIDIA Jetson Xavier.”
Does it have something to do with sustainability?
Professor Ogata illuminates, “Our DPL is not specific to opening and passing doors. It is a technology that enables a single robot to perform multiple tasks through learning. Compared to the use of multiple dedicated machines, the use of a single robot, which can increase its way of usage according to demand, will save a great deal of resources and make a significant contribution to sustainability.
It would be easier to understand if you imagine before and after the advent of smartphones.” He continues, “Our “Moonshot” project aims to make this idea a concrete reality. We developed a robot named AIREC in a large-scale project called Moonshot goal 3 supported by the Japanese cabinet.”

Mr. Ito with the robot.
How do the researchers perceive the acceptability of the system?
Professor Ogata elucidates, “Our DPL methodology is based on deep learning, which may cause anxiety to users in that its internal mechanisms are difficult to understand. Therefore, in our paper, we have made a particular effort to show the results of our analysis and visualization of the internal representation of the learning model.”
He continues, “We believe that by making the model as understandable as possible, we can alleviate the above concerns.”
Professor Ogata further states, “Also, some researchers working on human science and social science joined our Moonshot project. We will consider how to introduce our technologies with consideration of social acceptability.”

The research team.
Why and how is the current study significant for both robotics and understanding, and throwing insights into human structure as well?
The research area of cognitive developmental robotics captures human cognition and developmental processes through real robots. This field particularly emphasizes on embodied intelligence. Such a robotics research stream has been recognized as a basic research field. However, the researchers believe that their paper established the possibility that approaches of this research area can trigger the development of robots for executing actual applications.
What’s the future perspective of the current exploration?
According to Professor Ogata, “In the future, it will be important to research how to represent (self-organize) different levels of tasks in a deep predictive learning model.” He further says, “Moreover, for future applications, we plan to train a variety of tasks on AIREC: a robot being developed as part of the large-scale project called Moonshot goal 3 supported by the Japanese cabinet.” SV
Article Comments