Servo Magazine ( 2019 Issue-6 )
bots IN BRIEF (06.2019)
Getting Into Shape
Researchers at Northwestern University in Evanston have been working on a way to provide decentralized control for a swarm of 100 identically-programmed small robots, which allows them to collectively work out a way to transition from one shape to another without running into each other.

Northwestern researchers have built a swarm of 100 small mobile robots, each 12 cm tall and 10 cm in diameter. The robots share information and drive around to form shapes without collisions or deadlocks. Images courtesy of Northwestern University.
The process that the robots use to figure out where to go seems like it should be mostly straightforward. They’re given a shape to form, so each robot picks its goal location (where it wants to end up as part of the shape) and then plans a path to get from where it is to where it needs to go, following a grid pattern to make things a little easier.
Unfortunately, using this method, you immediately run into two problems: First, since there’s no central control, you may end up with two (or more) robots with the same goal location; and second, there’s no way for any single robot to plan its path all the way to its goal in a way that it can be certain it won’t run into another robot.
To solve these problems, the robots talk to each other as they move; not just to avoid colliding with the others, but also to figure out where the other bots are going and whether it might be worth swapping destinations.
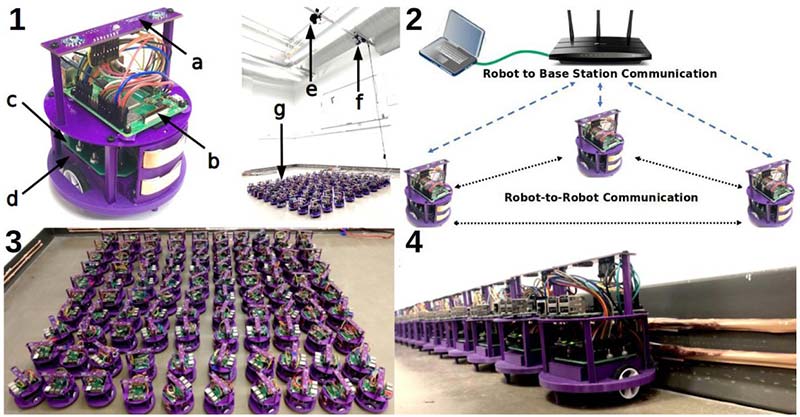
The hardware used by the researchers in their experiments. 1. The Coachbot V2.0 mobile robots (height of 12 cm and a diameter of 10 cm) are equipped with a localization system based on the HTC Vive (a), Raspberry Pi b+ computer (b), electronics motherboard (c), and rechargeable battery (d). The robot arena used in experiments has an overhead camera only used for recording videos (e) and an overhead HTC Vive base station (f). The experiments relied on a swarm of 100 robots (g). 2. The Coachbot V2.0 swarm communication network consists of an Ethernet connection between the base station and a Wi-Fi router (green link), TCP/IP connections (blue links), and layer 2 broadcasting connections (black links). 3. A swarm of 100 robots. 4. The robots recharge their batteries by connecting to two metal strips attached to the wall.
Since the robots are all the same, they don’t really care where exactly they end up, as long as all of the goal positions are filled up. If one robot talks to another robot and they agree that a goal swap would result in both of them having to move less, they go ahead and swap. The algorithm makes sure that all goal positions are filled eventually, and also helps robots avoid running into each other through the judicious use of a “wait” command.
What’s novel about this approach is that despite the fully distributed nature of the algorithm, it’s also provably correct, and will result in the guaranteed formation of an entire shape without collisions or deadlocks.
As far as the researchers know, it’s the first algorithm to do this. Since it’s effective with no centralized control at all, you can think of “the swarm” as a sort of Borg-like collective entity of its own, which is pretty cool.

Still images of a 100 robot shape formation experiment. The robots start in a random configuration, and move to form the desired “N” shape. Once this shape is formed, they then form the shape “U.” The entire sequence is fully autonomous. (a) T = 0 s; (b) T = 20 s; (c) T = 64 s; (d) T = 72 s; (e) T = 80 s; (f) T = 112 s.
The Northwestern researchers behind this are Michael Rubenstein, assistant professor of electrical engineering and computer science, and his PhD student Hanlin Wang. You might remember Mike from his work on Kilobots at Harvard, when Mike and his fellow researchers managed to put together a thousand robots. (Wowza!) When you think about what it takes to charge, fix, and modify a thousand robots, it makes sense why they’ve updated the platform a bit (now called Coachbot) and reduced the swarm size to 100 physical robots, making up the rest in simulation.
Plus, these robots are “much better behaved.”
AmbuBot Offers Alternative
Time is a critical issue when dealing with people affected by coronavirus and doctors could be far away from the patients. Additionally, avoiding direct contact with an infected person is a medical priority.
A robotic system developed at the AIART lab (Artificial Intelligence and Robotics Technology Laboratory), Department of Electrical Engineering, National Taipei University, Taiwan could be a solution to address those issues.
Ambulance Robot (AmbuBot) could be placed in various locations — especially in busy, remote, or quarantine areas — to assist in the above mentioned scenarios. The AmbuBot also brings along an AED in the sudden event of cardiac arrest, and facilitates various modes of operation from manual to semi-autonomous to autonomous functioning.
The ambulance robot can be operated remotely using the Internet, and doctors could instruct the local people for appropriate action. The robot could also carry a variety of required medical supplies, such as a thermometer, AED, coronavirus test kit, etc.
Doctors could have bi-directional communication via the robot equipped with audio-visual channels. They could even remotely operate the robot’s wheels and arm.

Guardian XO of the Galaxy
Sarcos has been making progress with its Guardian XO powered exoskeleton. The Sarcos Guardian XO full-body powered exoskeleton is a first-of-its-kind wearable robot that enhances human productivity while keeping workers safe from strain or injury. Set to transform the way work gets done, the Guardian XO exoskeleton augments operator strength without restricting freedom of movement to boost productivity while dramatically reducing injuries.

The Guardian XO is the world’s first battery-powered industrial robot to combine human intelligence, instinct, and judgment with the power, endurance, and precision of machines.

Music Man
Georgia Tech’s marimba-playing robot, Shimon can now compose and sing its own music. Shimon has performed in places like the Kennedy Center, and now has an album that will be released on Spotify soon, which features songs written (and sung) entirely by the robot.
Key to Shimon’s composing ability is its semantic knowledge: the ability to make thematic connections between things, which is a step beyond just throwing some deep learning at a huge database of music composed by humans. So, rather than just training a neural network that relates specific words that tend to be found together in lyrics, Shimon can recognize more general themes and build on them to create a coherent piece of music.

Image courtesy of Georgia Tech.
Just a Softy
Researchers at Stanford have developed a new kind of (mostly) soft robot based around a series of compliant air-filled tubes. It’s human scale, moves around, doesn’t require a pump or tether, is more or less as safe as large robots get, and even manages to play a little bit of basketball.

Images courtesy of Farrin Abbott.
The researchers refer to this kind of robot as “isoperimetric,” which means while discrete parts of the structure may change length, the overall length of all the parts put together stays the same. This means it’s got a similar sort of inherent compliance across the structure to tensegrity robots, which is one of the things that makes them so appealing.

While the compliance of Stanford’s robot comes from a truss-like structure made of air-filled tubes, its motion relies on powered movable modules. These modules pinch the tube they’re located on through two cylindrical rollers (without creating a seal). Driving the rollers moves the module back and forth along the tube, effectively making one section of the tube longer and the other one shorter. Although this is just one degree of freedom, having a whole bunch of tubes each with an independently controlled roller module means that the robot as a whole can exhibit complex behaviors, like drastic shape changes, movement, and even manipulation.
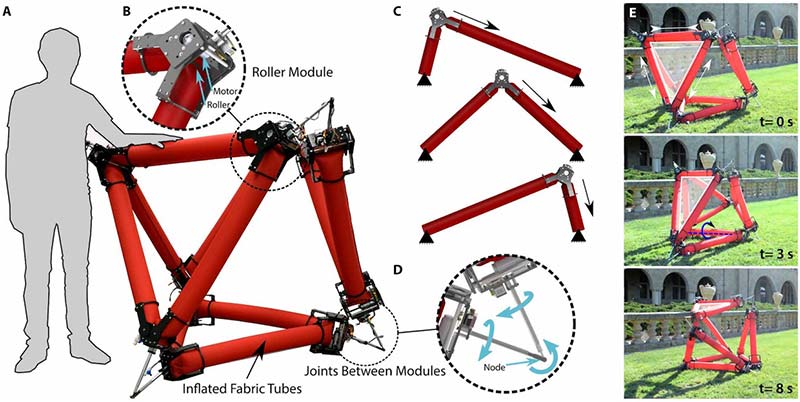
Stanford’s soft robot consists of a set of identical robotic roller modules mounted onto inflated fabric tubes (A). The rollers pinch the fabric tube between rollers, creating an effective joint (B) that can be relocated by driving the rollers. The roller modules actuate the robot by driving along the tube, simultaneously lengthening one edge while shortening another (C). The roller modules connect to each other at nodes using three-degree-of-freedom universal joints that are composed of a clevis joint that couples two rods, each free to spin about its axis (D). The robot moves untethered outdoors using a rolling gait (E). (Images courtesy of Stanford/Science Robotics.)
There are numerous advantages to a design like this. You get all the advantages of pneumatic robots (compliance, flexibility, collapsibility, durability, high strength-to-weight ratio) without requiring some way of constantly moving air around since the volume of air inside the robot stays constant.
Each individual triangular module is self-contained (with one tube, two active roller modules, and one passive anchor module) and easy to combine with similar modules.
UV Disinfection System
UVD Robots is a Danish company making robots that are able to disinfect patient rooms and operating theaters in hospitals. Each robot is a mobile array of powerful short wavelength ultraviolet-C (UVC) lights that emit enough energy to literally shred the DNA or RNA of any microorganisms that have the misfortune of being exposed to them.

Hundreds of these ultraviolet disinfection robots are being shipped to China to help fight the coronavirus outbreak.
The company’s robots have been operating in China, and UVD Robots CEO Per Juul Nielsen says they are sending more to China as fast as they can. The goal is to supply the robots to over 2,000 hospitals and medical facilities in China.
UV disinfecting technology has been around for a long time. It’s commonly used to disinfect drinking water. You have to point a UV lamp directly at a surface for a couple of minutes in order for it to be effective. Since it can cause damage to skin and eyes, humans have to be very careful around it.
UVD Robots spent four years developing a robotic UV disinfection system, which it started selling in 2018. The robot consists of a mobile base equipped with multiple LiDAR sensors and an array of UV lamps mounted on top. To deploy a robot, you drive it around once using a computer. The robot scans the environment using its LiDARs and creates a digital map. You then annotate the map indicating all the rooms and points the robot should stop to perform disinfecting tasks.
After that, the robot relies on simultaneous localization and mapping (SLAM) to navigate, and it operates completely on its own. It travels from its charging station, through hallways, up and down elevators if necessary, and performs the disinfection without human intervention before returning to recharge.
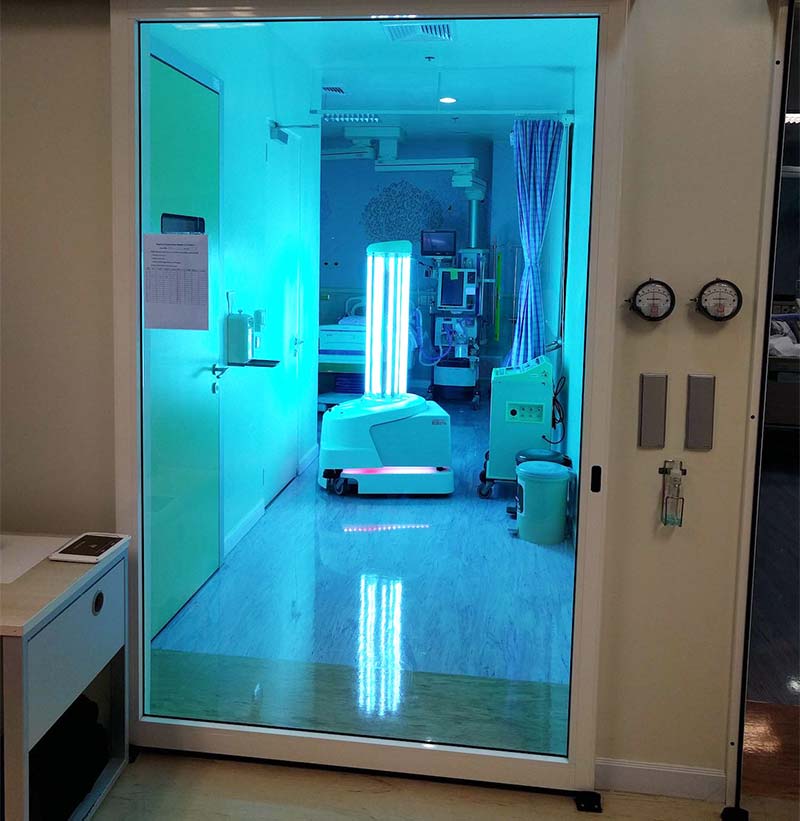
The robots can travel through hallways, up and down elevators if necessary, and perform the disinfection without human intervention before returning to recharge.
For safety, the robot operates when people are not around, using its sensors to detect motion and shutting the UV lights off if a person enters the area.
It takes between 10 and 15 minutes to disinfect a typical room, with the robot spending one or two minutes in five or six different positions around the room to maximize the number of surfaces that it disinfects. The robot’s UV array emits 20 joules per square meter per second (at a one meter distance) of 254-nanometer light, which will wreck 99.99 percent of germs in just a few minutes without the robot having to do anything more complicated than just sit there.
The process is more consistent than a human cleaning since the robot follows the same path each time, and its autonomy means that human staff can be freed up to do more important tasks like interacting with patients.

A shipment of robots from UVD Robots arrives at a hospital in Wuhan, where the first coronavirus cases were reported in December.
Vici Helps During Virus Outbreak
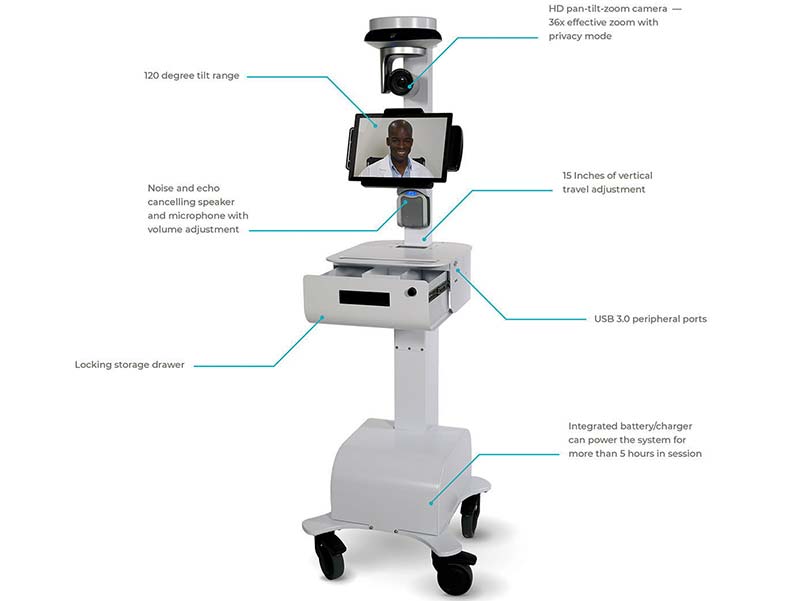
D octors are communicating with infected patients without exposing themselves to the virus by using a robot.
Since the coronavirus can transmit from person to person, doctors at the Washington state Providence Regional Medical Center are using Vici, which was developed by InTouch Health to treat patients.
“Telehealth devices like the robot assist caregivers in performing basic diagnostic functions and allow them to communicate easily with the patient,” Rebecca Bartles, the executive director of system infection prevention at Providence St. Joseph Health, told Digital Trends recently. “This helps reduce the number of up-close interactions which, in turn, minimizes the risk of exposure to caregivers.”
Vici has a high definition screen and camera, which allows a doctor or a nurse to help a patient without having to come in contact with them.
Vici is most commonly used for doctors located farther away to be able to chat with and examine their patients, but in this case, it’s for the health and safety of the hospital’s employees.
“The nursing staff in the room move the robot around so we can see the patient in the screen, talk to him,” Dr. George Diaz, chief of the infectious disease division at Providence, told CNN. “They’re looking for an ongoing presence of the virus.”
Drone Dodge Ball
The days of knocking an annoying drone out of the air with a precisely thrown rock might soon be over. Researchers at the University of Zurich have upgraded a drone with a special camera that can quickly spot approaching obstacles, allowing the craft to avoid them with reaction times as fast as 3.5 milliseconds.
Even drones being controlled by a skilled pilot can benefit from an obstacle avoidance system, which allows the craft to keep an eye out for obstacles in its flight path and automatically avoid a crash in the event a pilot doesn’t see a hazard or react fast enough to dodge it.
These types of systems are crucial for drones built to fly autonomously, whether it be for reconnaissance in dangerous areas after a natural disaster, or for companies like UPS that deliver products to consumers and have been developing flying drones as an alternative to four-wheeled delivery vehicles.
The cameras and image processing technologies that autonomous drones currently use to detect obstacles allow for reaction times within anywhere from 20 to 40 milliseconds, according to the UZH researchers. That’s fast, but when you factor in the speed of the drone itself (some can fly well over 150 miles per hour), with many obstacles (such as a flying bird, another drone, or even a static object), 20 milliseconds isn’t enough to avoid a collision.
The UZH researchers developed their own custom algorithms that are able to recognize threats detected by the event camera after sampling footage from a very short amount of time, while taking into account the speed and direction of the drone itself. The results are reaction times reduced down to just 3.5 milliseconds, making a drone far more effective at dodging a fast-moving obstacle.
In the future, the team aims to test this system on a more agile quadrotor. “Our ultimate goal is to make one day autonomous drones that navigate as good as human drone pilots. Currently, in all search and rescue applications where drones are involved, the human is actually in control. If we could have autonomous drones navigate as reliable as human pilots, we would then be able to use them for missions that fall beyond line of sight or beyond the reach of the remote control,” says Davide Falanga, PhD student.

The drone is able to successfully dodge balls, even if the ball is approaching it from a distance of three meters at 10 m/s. (Image courtesy of UZH.)
Getting the Finger
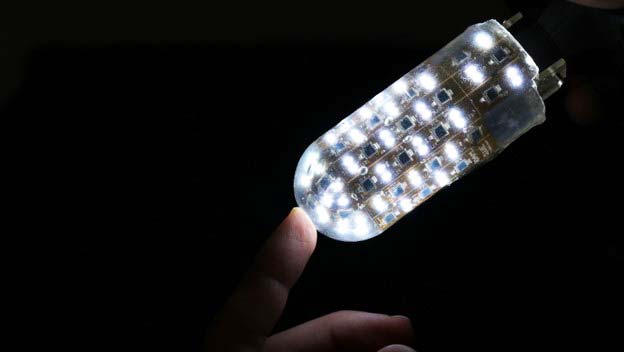
Researchers at Columbia Engineering have introduced a new type of robotic finger with a sense of touch. It can localize touch with very high precision over a large, multi-curved surface, much like a human finger.
Current methods for building touch sensors have proven difficult to integrate into robot fingers due to multiple challenges, including difficulty in covering multi-curved surfaces, high wire count, and difficulty fitting into small fingertips, thus preventing use in dexterous hands. The Columbia Engineering team took a new approach through the use of overlapping signals from light emitters and receivers embedded in a transparent waveguide layer that covers the functional areas of the finger.
HumANavigation
In a recent study, Google and University of California, Berkely researchers proposed a framework that combines learning-based perception with model-based controls to enable wheeled robots to autonomously navigate around obstacles. They say it generalizes well to avoiding unseen buildings and humans in both simulation and real world environments, and that it also leads to better and more data-efficient behaviors than a purely learning-based approach.
As the researchers explained, autonomous robot navigation has the potential to enable many critical robot applications, from service robots that deliver food and medicine, to logistical and search robots for rescue missions.
In these applications, it’s imperative for robots to work safely among humans and to adjust their movements based on observed human behavior. For example, if a person is turning left, the robot should pass the human to the right to avoid cutting them off and when a person is moving in the same direction as the robot, the robot should maintain a safe distance between itself and the person.
To this end, the researchers’ framework leverages a data set aptly dubbed Activate Navigation Dataset (HumANav), which consists of scans of 6,000 synthetic but realistic humans placed in office buildings. (Building mesh scans were sampled from the open source Stanford Large Scale 3D Indoor Spaces Dataset, but any textured building meshes are supported.)
It allows users to manipulate the human agents within the building and provides photorealistic renderings via a standard camera, ensuring that important visual cues associated with human movement are present in images, such as the fact that when someone walks quickly their legs will be further apart than if they’re moving slowly.
Jibo Disruption
NTT Disruption, a San Francisco-based company that is part of Japanese telecommunications company NTT Corporation, recently acquired assets from Jibo, the social robotics company that shut down in November 2018.
NTT Disruption acquired the following three patents from Jibo:
- Persistent Companion Device Configuration and Deployment Platform
- Embodied Dialog and Embodied Speech Authoring Tools for Use with an Expressive Social Robot
- Maintaining Attention and Conveying Believability via Expression and Goal-Directed Behavior with a Social Robot
One source recently told The Robot Report that NTT Disruption likely won’t re-start manufacturing of Jibo units for consumers. Rather, NTT will use the acquired assets to build custom products to use for its own business purposes.

Time for Good Behavior
In a new study, researchers at MIT’s Computer Science and Artificial Intelligence Lab proposed a framework called CommPlan, which gives robots that work alongside humans principles for “good etiquette” and leaves it to the robots to make decisions that let them finish tasks efficiently.
They claim it’s a superior approach to handcrafted rules, because it enables the robots to perform cost-benefit analyses on their decisions rather than follow task- and context-specific policies.
CommPlan weighs a combination of factors, including whether a person is busy or likely to respond given past behavior, leveraging a dedicated module (the Agent Markov Model) to represent that person’s sequential decision-making behaviors. It consists of a model specification process and an execution-time partially observable Markov decision process (POMDP) planner, derived as the robot’s decision-making model, which CommPlan uses in tandem to arrive at the robot’s actions and communications policies.
Using CommPlan, developers first specify these five modules with data, domain expertise, and learning algorithms: a task model; communication capability; a communication cost model; a human response model; and a human action-selectable model.
All modules are analytically combined to arrive at a decision-making model. During task execution, the robot computes its policy using hardware sensors, the decision-making model, and a POMDP solver. Finally, the policy is executed using the robot’s actuators and communication modality.
CommPlan communicates in the following ways:
- It informs and asks humans about the state of its decision-making (I am going to do action at landmark.“)
- It commands humans to perform specific actions and plans (“Where are you going?”)
- It answers human’s questions (“Please make the next sandwich at landmark.”)
The team reported that the robot successfully worked in conjunction with humans to complete tasks like assembling ingredients, wrapping sandwiches, and pouring juice, and it did so more safely and efficiently compared with baseline handcrafted and communications-free silent policies.
In the future, the researchers hope to extend CommPlan to other domains like health care, aerospace, and manufacturing. They’ve only used the framework for spoken language so far, but they say it could be applied to visual gestures, augmented reality systems, and others.

Having Good Sense
Ateam of researchers at UC Berkeley recently developed a new multi-directional tactile sensor called OmniTact that overcomes some of the limitations of previously developed sensors. OmniTact acts as an artificial fingertip that allows robots to sense the properties of objects they’re holding or manipulating.

A thumb next to OmniTact and a penny to show the size of the tactile sensor.
OmniTact (developed by Frederik Ebert, Akhil Padmanabha, and their colleagues) is an adaptation of GelSight: a tactile sensor created by researchers at MIT and UC Berkeley. GelSight can generate detailed 3D maps of an object’s surface and detect some of its characteristics.
In contrast with GelSight, OmniTact is multi-directional, which means that all of its sides have sensing capabilities. In addition, it can provide high-resolution readings, is highly compact, and has a curved shape.
When integrated into a gripper or robotic hand, the sensor acts as a sensitive artificial ‘finger,” allowing the robot to manipulate and sense a wide range of objects varying in shapes and sizes.
OmniTact was built by embedding multiple micro-cameras into an artificial skin made of silicone gel. The cameras detect multi-directional deformations of the gel-based skin, producing a rich signal that can then be analyzed by computer vision and image processing techniques to infer information about the objects that a robot is manipulating.
Ebert, Padmanabha, and their colleagues evaluated their sensor’s performance on a fairly challenging task where a robot had to insert an electrical connector into an outlet. They also tested its ability to infer the angle of contact of a finger as it pressed against a given object.
In these initial evaluations, OmniTact achieved remarkable results, outperforming both a tactile sensor that is only sensitive on one side and another multi-directional sensor in the state estimation task.
The researchers built their sensor using micro-cameras that are typically used in endoscopes, casting the silicone gel directly onto the cameras. As a result, OmniTact is far more compact than previously developed GelSight sensors and could thus have a broader range of possible applications. In the future, it could pave the way for the creation of new robots with more sophisticated sensing capabilities.
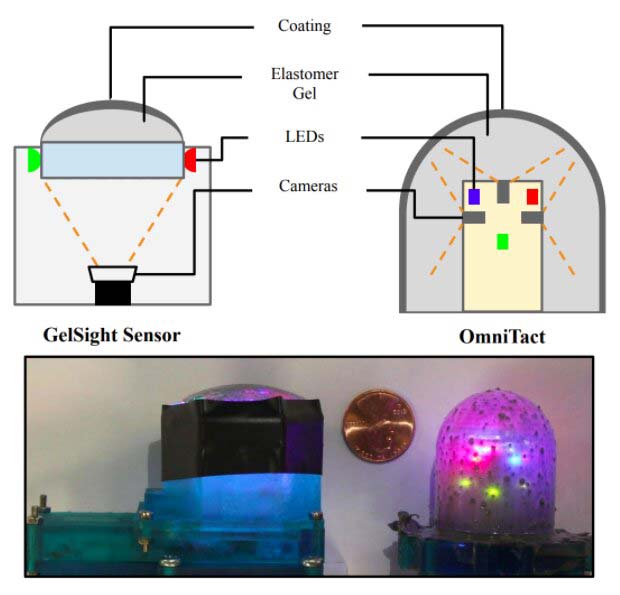
Basic differences between the GelSight Sensor and OmniTact. (Images courtesy of UC Berkeley.)
Senses in Low Places
Driver-assistance systems and autonomous vehicles in development use multiple sensors for navigation, collision avoidance, and monitoring the state of the vehicle and the driver. These include cameras, LiDAR, and radar. Radar offers advantages in being able to see through rain and snow, but what else can it do? WaveSense, Inc., is commercializing ground-penetrating radar that it says can provide additional useful data to vehicles and robots.
“We’re building the most robust and reliable positioning system for vehicles,” said Tarik Bolat, CEO of WaveSense. “It’s based on research originally done at MIT Lincoln Labs with military vehicles, and we got signals from the automotive industry that the technology should be brought into autonomous passenger vehicles.”
Unlike other sensing methods, ground-penetrating radar (GPR) is unaffected by snow, heavy rain, fog, or poor lane markings. In combination with GPS, cameras, and LiDAR GPR can significantly reduce navigation failure rates for autonomous and driver-assist systems.

GPR could make localization for self-driving cars more accurate.
WaveSense’s GPR could also help utility and construction companies, as well as delivery robots.
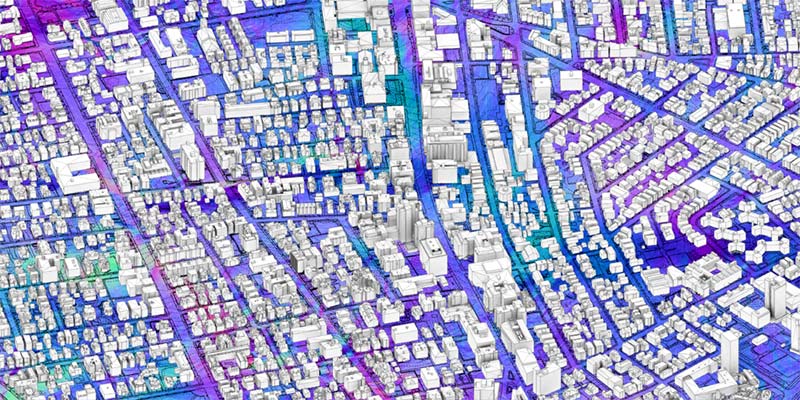
WaveSense is building maps with ground-penetrating radar. (Images courtesy of WaveSense.)
Pop-Up Goes the Robot
The newest edition of NASA’s small foldable robots recently practiced their scouting skills and successfully traversed rugged terrain in the Mars Yard at NASA’s Jet Propulsion Laboratory in Southern California.
JPL developed the Autonomous Pop-Up Flat Folding Explorer Robot (A-PUFFER) to scout regions on the Moon and gain intel about locations that may be difficult for astronauts to investigate on foot, like hard-to-reach craters and narrow caves.
A “pop-up” robot that folds into a small, smartphone-sized weight and volume can be packed into a larger parent craft at a low payload cost, then deployed on a planet’s surface individually to increase surface mobility.

Do As I Do
Training interactive robots may soon be an easy job for everyone — even those without programming expertise. Roboticists are developing automated robots that can learn new tasks solely by observing humans.
Making progress on that vision, researchers at the Massachusetts Institute of Technology (MIT) have designed a system that lets robots learn complicated tasks that would otherwise stymie them with too many confusing rules. One such task is setting a dinner table under certain conditions.
At its core, the researcher’s “Planning with Uncertain Specifications” (PUnS) system gives robots the human-like planning ability to simultaneously weigh many ambiguous — and potentially contradictory — requirements to reach an end goal. In doing so, the system always chooses the most likely action to take, based on a “belief” about some probable specifications for the task it’s supposed to perform.
In their work, the researchers compiled a dataset with information about how eight objects (a mug, glass, spoon, fork, knife, dinner plate, small plate, and bowl) could be placed on a table in various configurations.
A robotic arm first observed randomly selected human demonstrations of setting the table with the objects. Then, the researchers tasked the arm with automatically setting a table in a specific configuration in real world experiments and in simulation based on what it had seen.
To succeed, the robot had to weigh many possible placement orderings, even when items were purposely removed, stacked, or hidden. Normally, all of that would confuse robots too much. However, the robot made no mistakes over several real world experiments, and only a handful of mistakes over tens of thousands of simulated test runs.

MIT is developing robots that can learn new tasks solely by observing humans. (Image courtesy of Christine Daniloff/MIT.)
Article Comments